
Our platform enables you to quickly and easily connect your data sources to data from a File Key/Location in Amazon S3 Storage.
This enables a one-way synchronization to occur - where any changes in the Amazon S3 Storage File Key/Location are downloaded into your data source on a regular basis.
Your data source will be automatically updated in this way until you remove the connector or an error occurs (such as losing authorization to access the file).
Note: You need to have configured a Connection to your Amazon S3 Storage account before adding a Connector.- Adding an Amazon S3 Data Source Connector
- Configuring an Amazon S3 Data Source Connector
Adding an Amazon S3 Data Source Connector
Navigate to the Settings page of the data source you'd like to import rows into.
- Connected Data>Data Sources
- In the list of available data sources, hover your mouse over the listing of the data source you wish to connect.
A set of options will show, click on the Settings link. On the Settings page, after Basic and Advanced Options is the Connector option, click the Add Connector link.

- A new window with connectors to choose from will appear, click the Amazon S3 Storage option.



The page should refresh with your newly added connector to be configured.
Configuring an Amazon S3 Data Source Connector
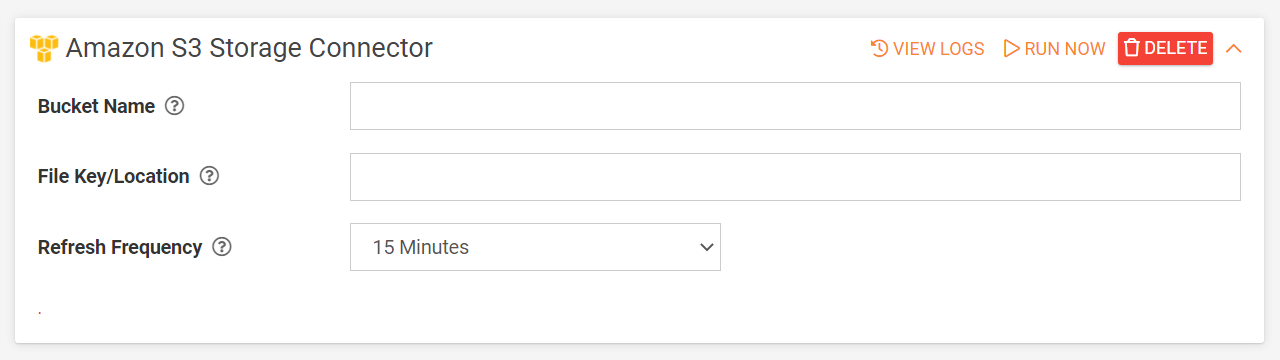
Next, configure the following:
- Bucket Name
Enter the name of the Bucket the file is stored in. - File Key/Location
Specify the location which uniquely identifies the file within the S3 bucket.
For example:
Development/Projects1.xls
Finance/statement1.csv - Refresh Frequency
The frequency that data is pulled by this connector.
Note: Data must be in .csv or .xlsx format and cannot contain formulae. The spreadsheet must exist in your connected Amazon S3 Storage account.
Wait a minute or so and then check the Rows page of your data source.
Was this article helpful?
That’s Great!
Thank you for your feedback
Sorry! We couldn't be helpful
Thank you for your feedback
Feedback sent
We appreciate your effort and will try to fix the article
